
05.group.md 4.3 KB
分组、聚合函数
--建表#employees
create table employees(
number char(8) primary key,
name char(20) not null,
department char(20) null,
age int null,
salary decimal(6,2)not null,
jointime datetime not null,
Job_title char(30) null
)
insert into employees values('11080301', '张三', '工程处', 46, 5888.88, '1999-12-01 15:38:00.000', '主任')
insert into employees values('11080302', '李四', '信息部', 50, 4666.58, '1998-09-01 15:38:00.000', '副主任')
insert into employees values('11080303', '张小六', '动力处', null, 4008.48, '1989-12-01 15:38:00.000', '职员')
insert into employees values('11080304', '刘大无', '工程处', 30, 3226.68, '1996-09-01 15:38:00.000', '职员')
insert into employees values('11080305', '张小七', '工程处', null, 2818.38, '2000-12-01 15:38:00.000', '职员')
如表1

一、分组
使用 group by 可以对数据进行分组。所谓分组就是按照列的相同内容,将记录划分成不同的组。
单列 group by:
select department from employees group by department

对多列进行 group by:
select department, Job_title from employees group by department, Job_title

二、聚合函数
聚合函数对一组值计算后返回单个值,除了 count(统计项数) 函数以外,其他的都聚合函数在计算式都会忽略空值(null)。所有的聚合函数均为确定性函数,即任何时候使用一组相同的输入值调用聚合函数执行后的返回值都是相同的。
聚合函数通常会在下列场合使用:
1、select 语句的选择列表,包括子查询和外部查询。
2、使用 rollup 或 cube 产生汇总列时。
3、having 子句对分组的数据记录进行条件筛选。
常用聚合函数,如下所示:
count([all|distinct] expression|*) 统计记录个数
sum([all|distinct] expression) 计算指定表达式的总和
avg([all|distinct] expression) 计算指定表达式的平均值
max([all|distinct] expression) 计算指定表达式中的最大值
min([all|distinct] expression) 计算指定表达式中的最小值
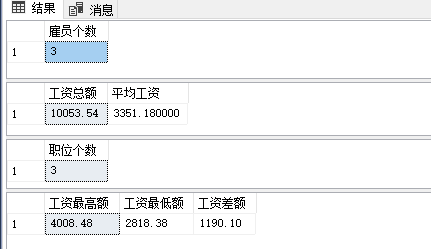
select count(age) 雇员个数 from employees --查询已填写年龄的所有雇员记录个数
select sum(salary) 工资总额, avg(salary) 平均工资 from employees where Job_title = '职员' --查询职位为职员的雇员的工资总额和平均工资
select count(distinct Job_title) 职位个数 from employees --查询不重复的工人职位的个数
select max(salary) 工资最高额, min(salary) 工资最低额, max(salary)-min(salary) 工资差额 from employees where Job_title = '职员' --查询职位为职员的工人的工资最高额、最低额及相差的额度
分组一般和聚合函数连用,通过 group by 子句可以对查询结果分组,分组的目的是为了细化聚集函数的作用对象。
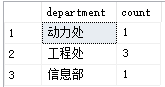
示例:查询不同部门的雇员个数
select department, count(*) count from employees group by department
结果:
示例说明:
(1)不能在 group by 子句中引用计算列,即不能按照计算列进行分组。
(2)在“目标列”中只能出现在 group by 子句引用的列或聚集函数列。例:
> select department, Job_title, name from employees group by department, Job_title > ``` > >  ## 三、having 可以在包含 group by 子句的查询中使用 where 子句。在完成任何分组之前,将消除不符合 where 子句中的条件的行。若在分组后还要按照一定的条件进行筛选,则需使用 having 子句。 示例:查询雇员所在部门中有两个以上雇员的部门名称。 ```sql select department from employees group by department having count(*) >= 2
结果:

上例中先用 group by 子句按 department 分组,再使用聚集函数 count(*) 对每个分组进行计数,通过 having 子句只输出分组计数值大于等于2的分组结果。
where 子句与 having 子句的区别在于作用对象不同。where 子句作用于关系表,从中选择满足条件的记录;having 子句作用于分组,从中选择满足条件的分组。