
 wanglilin
wanglilin
8 змінених файлів з 114 додано та 3 видалено
+ 114
- 3
sql/05.group.md
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
|
||
BIN
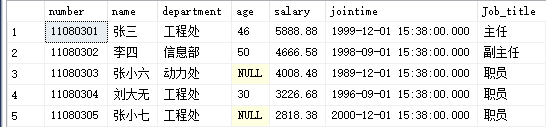
sql/static/images/05_01.png
{kind=link}
BIN
sql/static/images/05_02.png
{kind=link}

BIN
sql/static/images/05_03.png
{kind=link}

BIN
sql/static/images/05_04.png
{kind=link}

BIN
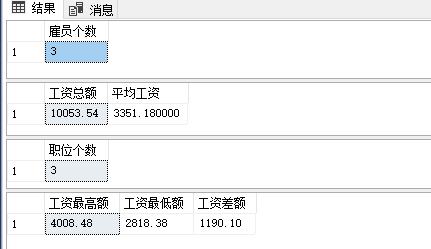
sql/static/images/05_05.png
{kind=link}
BIN
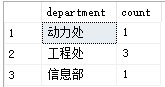
sql/static/images/05_06.png
{kind=link}
BIN
sql/static/images/05_07.png
{kind=link}
