efcoreжңҖдҪіе®һзҺ°.md 12 KB
жӣҙеҘҪең°жҺҢжҸЎ EntityFramework ж ёеҝғ--жңҖдҪіе®һи·ө
жҲ‘дјҡеңЁеҸ‘зҺ°ж–°зҡ„е®һи·өеҗҺпјҢжҢҒз»ӯжӣҙж–°иҝҷзҜҮж–Үз« гҖӮ
еҜ№дәҺ .NET ејҖеҸ‘дәәе‘ҳжқҘиҜҙпјҢEntityFramework жҳҜдёҖдёӘи¶…зә§жҳ“з”Ёзҡ„ ORM еә“гҖӮиҷҪ然пјҢе°Ҫз®Ўе®ғдҪҝз”Ёж–№дҫҝпјҢиҖҢдё”е…·жңүеҚіжҸ’еҚіз”Ёзҡ„еҠҹиғҪпјҢдҪҶиҖҒе®һиҜҙпјҢиҰҒжҠҠе®ғеҒҡеҘҪжҳҜзӣёеҪ“еӣ°йҡҫзҡ„гҖӮ
зӣ®еҪ•
- и§ЈеҶіж–№жЎҲе’ҢйЎ№зӣ®з»“жһ„
- е®үе…ЁжҖ§
- йўҶеҹҹжЁЎеһӢ
- dotnet ef CLI
- иҝҒ移
и§ЈеҶіж–№жЎҲе’ҢйЎ№зӣ®з»“жһ„
рҹ‘Қ е°ҶеӣҫеұӮеҲҶзҰ»еҲ°дёҚеҗҢзҡ„йЎ№зӣ®дёӯ
дёӢйқўзҡ„и§ЈеҶіж–№жЎҲз»“жһ„жҳҜжҲ‘з»Ҹеёёи§үеҫ—жңҖжңүз”Ёзҡ„дёҖз§Қ:

е®ғеҸҜд»Ҙи®©дҪ е№ІеҮҖеҲ©иҗҪең°еҲҶзҰ»еә”з”Ёзҡ„иҙЈд»»гҖӮ
рҹ‘Қ еҸӘжңү DataLayer йЎ№зӣ®еә”иҜҘеҜ№ EntityFramework жңүдҫқиө–жҖ§--2020 е№ҙ 4 жңҲ 21 ж—Ҙжӣҙж–°гҖӮ
жҢҒд№…жҖ§е®һзҺ°зҡ„з»ҶиҠӮеә”иҜҘеҸӘжңүж•°жҚ®еұӮзҹҘйҒ“гҖӮ
ж•°жҚ®еұӮеҝ…йЎ»е®һзҺ°е…¶д»–йЎ№зӣ®дёӯе®ҡд№үзҡ„жҺҘеҸЈпјҢиҝҷдәӣзұ»зҡ„е…·дҪ“е®һзҺ°еә”иҜҘеңЁдҪ йҖүжӢ©зҡ„дҫқиө–е®№еҷЁдёӯжіЁеҶҢгҖӮ
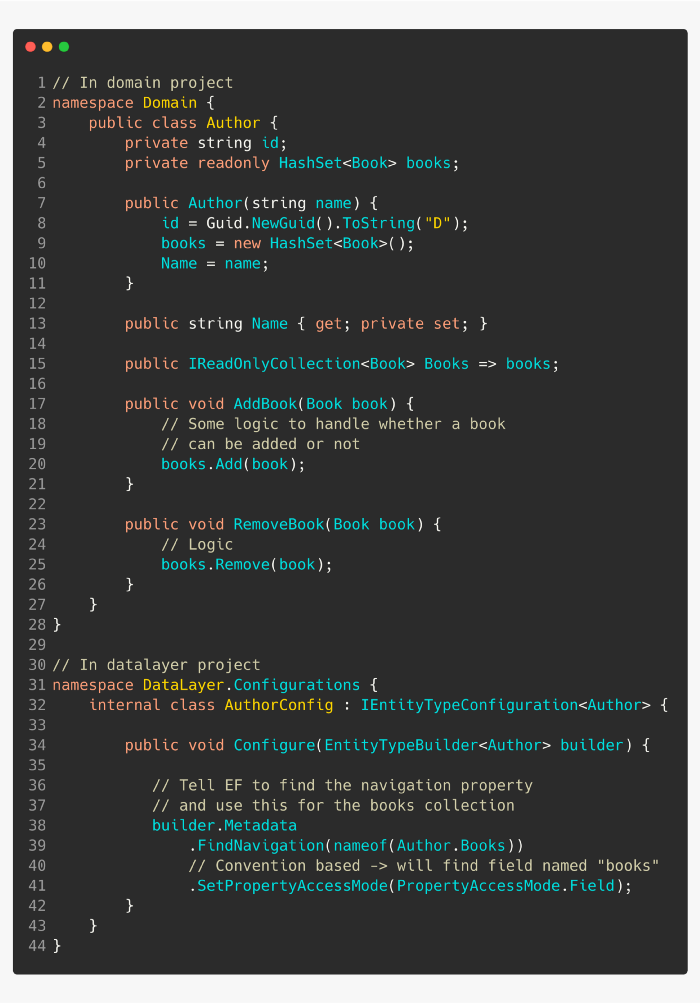
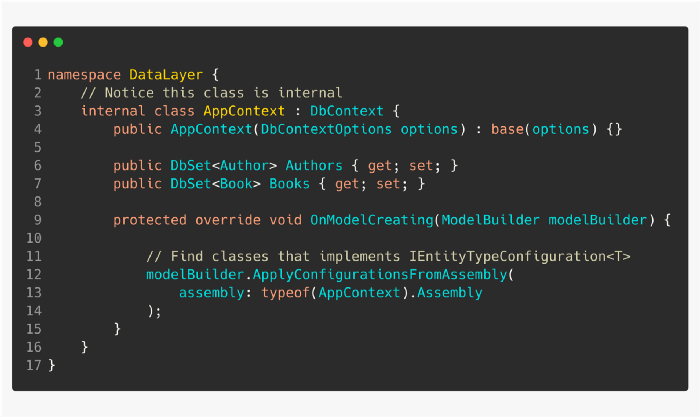
рҹ‘Қ е°Ҷ DbContext зұ»дҝқжҢҒеңЁ DataLayer йЎ№зӣ®зҡ„еҶ…йғЁгҖӮ
еңЁ DataLayer дёӯеҲӣе»әдёҖдёӘе®ўжҲ·з«ҜеҸҜд»ҘдҪҝз”Ёзҡ„ IServiceCollection жү©еұ•ж–№жі•гҖӮиҜҘж–№жі•еә”иҜҘеҗ‘дҫқиө–жіЁе…ҘжЎҶжһ¶жіЁеҶҢ DbContextгҖӮ
е®ўжҲ·з«ҜдёҚеә”иҜҘзҹҘйҒ“жҲ–е…іеҝғжҢҒд№…жҖ§гҖӮ

еңЁе®ўжҲ·з«ҜйЎ№зӣ®зҡ„ Startup зұ»дёӯдҪҝз”Ё IServiceCollectionгҖӮ
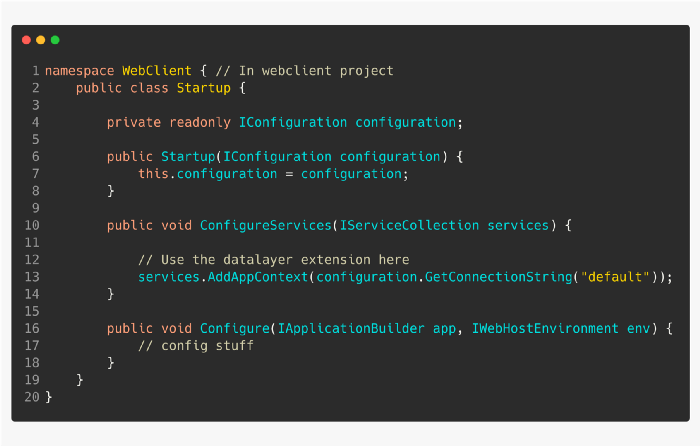
е°ҒиЈ…ж•°жҚ®еә“дёҠдёӢж–ҮеҸҜд»ҘдҝқиҜҒе®ўжҲ·з«ҜдёҚдјҡзӣҙжҺҘи®ҝй—®иҝӣиЎҢж•°жҚ®еә“и°ғз”ЁпјҢеҸҰеӨ–пјҢе®ўжҲ·з«ҜйЎ№зӣ®дёҚдјҡеҜ№ EntityFrameworkCore дә§з”ҹдёҚеҝ…иҰҒзҡ„дҫқиө–гҖӮ
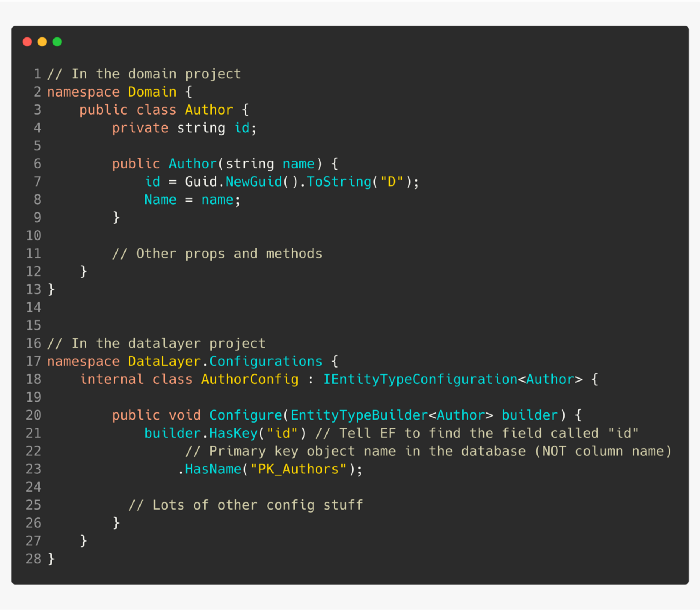
рҹ‘Қ еңЁ OnModelCreating()дёҠдҪҝз”Ёзұ»еһӢй…ҚзҪ®гҖӮ
еңЁеҲӣе»ә DbContext ж—¶пјҢеҫҲе®№жҳ“зӣҙжҺҘеңЁ OnModelCreating(Modelbuilder builder)ж–№жі•йҮҢйқўй…ҚзҪ®еҹҹжЁЎеһӢгҖӮдҪҶжҳҜиҝҷз§Қж–№жі•дјҡеҫҲеҝ«еҸҳеҫ—ж··д№ұгҖӮ
зӣёеҸҚпјҢеҸӘдҪҝз”Ё OnModelCreating жқҘжү«жҸҸжү§иЎҢе®һдҪ“й…ҚзҪ®зҡ„зұ»еһӢгҖӮ
然еҗҺеҲӣе»әеҚ•зӢ¬зҡ„дё“з”Ёзұ»пјҢз”ЁдәҺй…ҚзҪ®жӮЁж·»еҠ еҲ° DbSet<T>зҡ„дёҚеҗҢзұ»еһӢгҖӮ

еңЁ Configure(builder)`йҮҢйқўпјҢдҪ дјҡз”Ё FluentApi еҶҷеҮәжүҖжңүж•°жҚ®еә“зү№е®ҡзҡ„жЁЎеһӢй…ҚзҪ®гҖӮ
е®үе…ЁжҖ§
йҖҡиҝҮдҪҝз”ЁеҶ…зҪ®зҡ„.NET еҜҶй’Ҙз®ЎзҗҶеҷЁпјҢдёҚжғңдёҖеҲҮд»Јд»·йҒҝе…ҚжЈҖжҹҘдҪ зҡ„ ConnectionStringгҖӮ
иҜ·жіЁж„ҸпјҢжӮЁеҸҜиғҪйңҖиҰҒж·»еҠ иҝҷдёӘ nuget еҢ…пјҡMicrosoft.Extensions.Configuration.UserSecrets еҲ°дҪ зҡ„йЎ№зӣ®дёӯгҖӮ
з”ЁжҲ·зҡ„еҜҶй’ҘеӯҳеӮЁеңЁпјҡ
Windows %APPDATA%\Microsoft\UserSecrets<user_secrets_id>\secrets.json Mac ~/.microsoft/usersecrets//secrets.json
жҢүз…§д»ҘдёӢжӯҘйӘӨж·»еҠ з”ЁжҲ·еҜҶй’Ҙ:
- еңЁдҪ зҡ„ AppSettings дёӯпјҢж·»еҠ ConnectionString еұһжҖ§гҖӮе®ғеҸҜиғҪзңӢиө·жқҘеғҸдёӢйқўзҡ„зүҮж®ө--йҮҚиҰҒзҡ„жҳҜиҜҘеҖјдёәз©әгҖӮ
# appsettings.json { "ConnectionStrings": { "default": "" }, // Some other properties }
- дҪҝз”Ё terminl е°Ҷзӣ®еҪ•ж”№дёәдҪ зҡ„е®ўжҲ·з«ҜйЎ№зӣ®гҖӮдҫӢеҰӮпјҢдҪ зҡ„ ASP.NET Web еә”з”ЁзЁӢеәҸзҡ„ж №зӣ®еҪ•гҖӮ
cd To/Path/Of/Startup/Root
- еҲқе§ӢеҢ–з”ЁжҲ·зҡ„еҜҶй’ҘпјҢ并и®ҫзҪ® ConnectionStringгҖӮ
dotnet user-secrets init dotnet user-secrets set "ConnectionStrings:default" "connection_string"рҹ‘Қ еҜ№дәҺз”ҹдә§пјҢе°ҶеҜҶй’ҘеӯҳеӮЁеңЁ KeyVault жҲ–зҺҜеўғеҸҳйҮҸдёӯгҖӮ
жңҖеҘҪзҡ„и§ЈеҶіж–№жЎҲжҳҜе°ҶеҜҶй’ҘеӯҳеӮЁеңЁ KeyVault дёӯпјҢдҫӢеҰӮ Azure KeyVaultгҖӮдҪҶжҳҜпјҢд№ҹеҸҜиғҪеҸӘйңҖе°Ҷе®ғ们еӯҳеӮЁдёәзҺҜеўғеҸҳйҮҸпјҢжҲ–еӯҳеӮЁеңЁдҪҚдәҺ Web жңҚеҠЎеҷЁжң¬иә«зҡ„ AppSettings.json ж–Ү件дёӯеҚіеҸҜгҖӮ
рҹ‘Қ дёәеә”з”ЁеҲӣе»әдёҖдёӘзӢ¬з«Ӣзҡ„ж•°жҚ®еә“зҷ»еҪ•еҗҚе’Ңз”ЁжҲ·гҖӮ
еғҸе…¶д»–ж•°жҚ®еә“зҡ„жҷ®йҖҡз”ЁжҲ·дёҖж ·жҹҘзңӢеә”з”ЁзЁӢеәҸгҖӮ
дёҮдёҖжңүдәәиҜҜе°Ҷ db з”ЁжҲ·е’ҢеҜҶз ҒжЈҖжҹҘеҲ°жәҗз ҒжҺ§еҲ¶дёӯпјҢеҸӘйңҖзҰҒз”Ёеә”з”ЁзЁӢеәҸзҡ„ db з”ЁжҲ·е№¶еҲӣе»әдёҖдёӘж–°зҡ„з”ЁжҲ·пјҢжҜ”дҪ зҡ„жңҚеҠЎеҷЁз®ЎзҗҶе‘ҳпјҲsaпјүзҷ»еҪ•е’Ң dbo з”ЁжҲ·иў«жі„йңІзҡ„д»Јд»·иҰҒе°ҸгҖӮ
рҹҡЁ еә”з”ЁзЁӢеәҸзҡ„ DB з”ЁжҲ·дёҚиғҪжңүдёҚеҝ…иҰҒзҡ„жқғйҷҗгҖӮ
дҪ дјҡз»ҷдҪ зҡ„з»„з»ҮжҲ–еӣўйҳҹдёӯзҡ„д»»дҪ•дәәиөӢдәҲжөӢиҜ•жҲ–з”ҹдә§ж•°жҚ®еә“зҡ„и¶…зә§з®ЎзҗҶжқғйҷҗеҗ—пјҹ
ж №жҚ®жңҖе°ҸжқғйҷҗеҺҹеҲҷпјҢеҗ‘еә”з”ЁзЁӢеәҸзҡ„ж•°жҚ®еә“з”ЁжҲ·жҺҲдәҲжқғйҷҗгҖӮеә”з”ЁзЁӢеәҸеә”иҜҘеҸӘжӢҘжңүжү§иЎҢе…¶е·ҘдҪңзҡ„жңҖдҪҺйҷҗеәҰзҡ„жқғйҷҗгҖӮ
рҹ‘Қ д»ҺдёҖдёӘдёҚеҗҢдәҺеә”з”ЁзЁӢеәҸжӯЈеңЁдҪҝз”Ёзҡ„ DB з”ЁжҲ·дёӯиҝҗиЎҢиҝҒ移и„ҡжң¬
иҜҘе»әи®®дёҺиҒҢиҙЈеҲҶзҰ»жңүе…ігҖӮеә”з”ЁзЁӢеәҸдёҚеә”иҙҹиҙЈеҲӣе»әж•°жҚ®еә“еҸҠе…¶иЎЁгҖӮеә”з”ЁзЁӢеәҸеә”иҜҘеҸӘжҳҜеҜ№иҝҷдәӣеҜ№иұЎиҝӣиЎҢж“ҚдҪңгҖӮ
йўҶеҹҹжЁЎеһӢ
рҹ‘Қ жҢҒз»ӯжҖ§ж— и§Ҷ
дё“жіЁдәҺеҜ№дҪ зҡ„йўҶеҹҹиҝӣиЎҢе»әжЁЎгҖӮе°ҪйҮҸдёҚиҰҒеҺ»жғідҪ дҪҝз”Ёзҡ„жҳҜе“ӘдёӘ ORMгҖӮ
дҪҶжҳҜпјҢиҰҒе®һдәӢжұӮжҳҜгҖӮ
жңүж—¶еҖҷпјҢеҪ“иЎЁзҺ°еҫ—еғҸжҢҒд№…жҖ§дёҚеӯҳеңЁж—¶пјҢи®©дәӢжғ…иҝҗиҪ¬иө·жқҘз®ҖзӣҙеӨӘйә»зғҰдәҶгҖӮиҖғиҷ‘дёҖдёӢдҪ зҡ„з”ЁдҫӢпјҢд»ҘеҸҠдҪ еёҢжңӣдҪ зҡ„д»Јз ҒжңүеӨҡзҒөжҙ»е’ҢжЁЎеқ—еҢ–гҖӮ
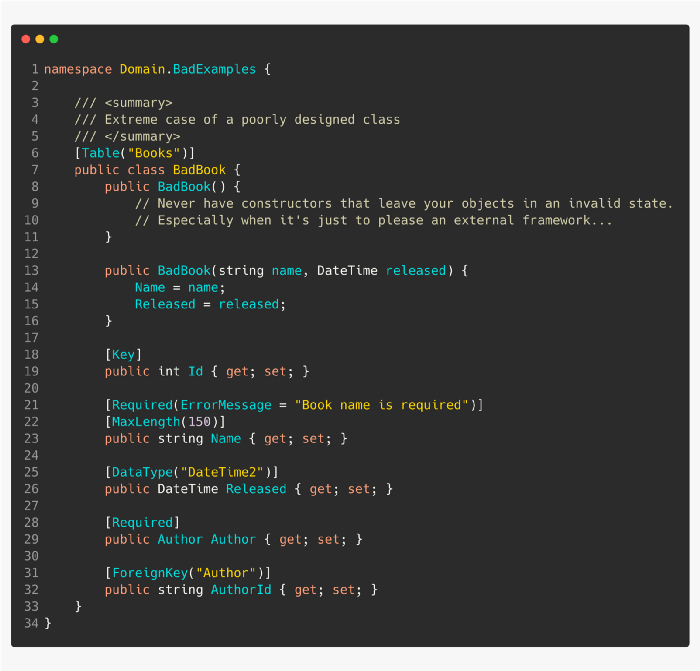
рҹҡЁ йҒҝе…Қж•°жҚ®жіЁйҮҠгҖӮ
йҒҝе…ҚдҪҝз”Ё[Table], [Column], [Key], [ForeignKey]зӯүеұһжҖ§гҖӮ
дҪҝз”ЁеҚ•зӢ¬зҡ„ж•°жҚ®еұӮйЎ№зӣ®пјҢеҜ№ Domain йЎ№зӣ®иҝӣиЎҢдҫқиө–пјҢ并дҪҝз”Ё IEntityTypeConfiguration<T>еҜ№жүҖжңүжЁЎеһӢиҝӣиЎҢй“ҫжҺҘгҖӮ
рҹ‘Қ дҝқжҢҒ ID зҡ„з§ҒеҜҶжҖ§
йҷӨдәҶж–№дҫҝд№ӢеӨ–пјҢдҪ еҫҲе°‘дјҡжғіжҡҙйңІ IDгҖӮ
еңЁеғҸ api/author/1 иҝҷж ·зҡ„ urls дёӯжҡҙйңІ ID еҸҜиғҪдјҡеҜјиҮҙй—®йўҳпјҢжҜ”еҰӮеҰӮжһң MS SQL жңҚеҠЎеҷЁе·Із»Ҹеҙ©жәғжҲ–йҮҚеҗҜпјҢдёӢдёҖдёӘ ID еҸҜиғҪжҳҜ 1001гҖӮжҲ‘жңүе®ўжҲ·иҜ„и®әиҝҮиҝҷдёӘй—®йўҳпјҢеқҡжҢҒи®ӨдёәиҝҷжҳҜдёҖдёӘеҝ…йЎ»и§ЈеҶізҡ„ bugгҖӮ
еҰӮжһңдҪ иҜ•еӣҫз”ЁдёҖдёӘжңүз§Ғжңү id еӯ—ж®өзҡ„зұ»жқҘз”ҹжҲҗиҝҒ移пјҢEF core дјҡжҠҘй”ҷпјҢеӣ дёәе®ғж— жі•жүҫеҲ°дёҖдёӘ ID жқҘдҪңдёәдё»й”®гҖӮдҪҝз”Ёзұ»еһӢй…ҚзҪ®еҸҜд»ҘиҪ»жқҫи§ЈеҶіиҝҷдёӘй—®йўҳпјҢеҰӮдёӢеӣҫжүҖзӨәпјҡ
дёҺе…¶дҪҝз”Ё ID жҹҘиҜўпјҢдёҚеҰӮдҪҝз”ЁеҸҰдёҖдёӘе”ҜдёҖзҡ„еұһжҖ§пјҢжҲ–иҖ…пјҢеұһжҖ§зҡ„з»„еҗҲгҖӮ
еңЁдёҚзЎ®е®ҡзҡ„жғ…еҶөдёӢпјҢMedium ж–Үз« дјјд№ҺдҪҝз”ЁдәҶдҪңиҖ…еҸҘжҹ„гҖҒж–Үз« еҗҚе’ҢйҡҸжңәеӯ—з¬ҰдёІзҡ„ж··еҗҲгҖӮ
nmillard/entityframework-core-dont-get-burnt-in-production-335ddfcfdfdaеҰӮжһңдҪ еҝ…йЎ»е…¬ејҖжҡҙйңІ IDпјҢеҸҜд»Ҙе°қиҜ•дҪҝз”Ёе…¶д»–дёңиҘҝиҖҢдёҚжҳҜж•ҙж•°гҖӮ
рҹ‘Қ иҮӘе·ұз”ҹжҲҗ ID
дёҚиҰҒи®©ж•°жҚ®еә“зӯү第дёүж–№иҪҜ件жқҘз”ҹжҲҗдҪ зҡ„еҹҹеҗҚ IDгҖӮдҪ еә”иҜҘе®Ңе…ЁжҺ§еҲ¶е®ғ们зҡ„з”ҹжҲҗгҖӮе®ғ们е®һеңЁжҳҜеӨӘйҮҚиҰҒдәҶгҖӮ
жҲ‘йҖҡеёёйҮҮз”ЁдёӨз§Қж–№ејҸд№ӢдёҖжқҘеӨ„зҗҶиҝҷдёӘй—®йўҳгҖӮ1пјүи®©йўҶеҹҹжЁЎеһӢиҮӘе·ұз”ҹжҲҗ IDпјҢжҜ”еҰӮеңЁе®һдҫӢеҢ–ж—¶еҲҶй…ҚдёҖдёӘ GUIDпјҢжҲ–иҖ… 2пјүдҪҝз”ЁдёҖдёӘ ID е·ҘеҺӮпјҢ并е°Ҷз”ҹжҲҗзҡ„ ID дј йҖ’з»ҷжЁЎеһӢзҡ„жһ„йҖ еҮҪж•°гҖӮ
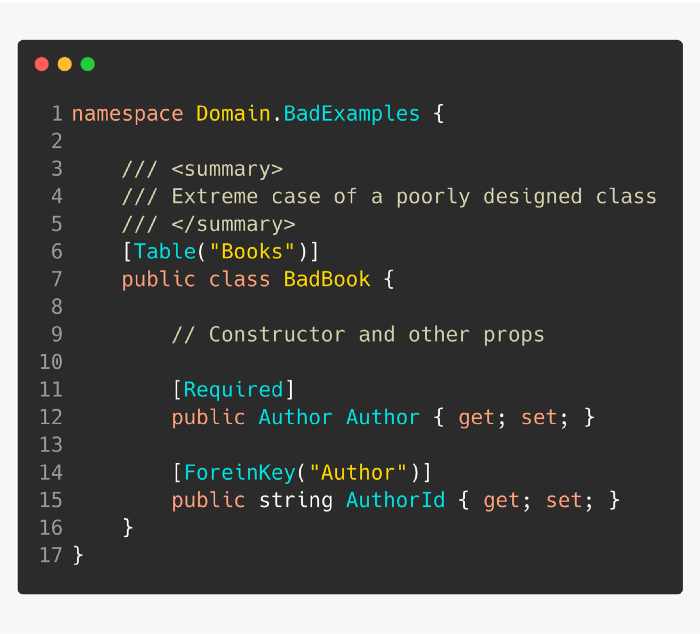
рҹҡЁ йҒҝе…ҚеҹҹжЁЎеһӢдёӯзҡ„еӨ–й”®еұһжҖ§гҖӮ
рҹ‘Қ еҪ“ EF дёҚиғҪз”ҹжҲҗеӨ–й”®еҲ—ж—¶пјҢдҪҝз”ЁеҪұеӯҗеұһжҖ§--2020 е№ҙ 4 жңҲ 1 ж—Ҙж·»еҠ гҖӮ
рҹҡЁ йҒҝе…ҚдҪҝз”Ёе…¬е…ұзјәзңҒжһ„йҖ еҮҪж•°гҖӮ
дёҚиҰҒдёәдәҶи®© EF Core й«ҳе…ҙиҖҢеҒҡе…¬е…ұзҡ„зјәзңҒжһ„йҖ еҮҪж•°пјҢиҖҢжҳҜиҰҒжҠҠзјәзңҒжһ„йҖ еҮҪж•°еҒҡжҲҗз§Ғжңүзҡ„гҖӮ
еҰӮжһңиҝһдёҖдёӘз§Ғжңүзҡ„жһ„йҖ еҮҪж•°йғҪдёҚеӨҹеҘҪпјҢд№ҹеҸҜд»ҘжңүеҸӮж•°еҢ–зҡ„жһ„йҖ еҮҪж•°гҖӮдёҚиҝҮпјҢдҪ еә”иҜҘжіЁж„Ҹиҝҷз§ҚиЎҢдёәгҖӮ
- еҸӮж•°е’ҢеұһжҖ§зұ»еһӢе’ҢеҗҚз§°еҝ…йЎ»еҢ№й…Қ--дҪҶеҸӮж•°еҗҚз§°еҸҜд»Ҙз”Ёй©јеі°еӨ§еҶҷпјҲеҰӮ ThisпјүгҖӮ
- дёҚиғҪи®ҫзҪ®еҜјиҲӘеұһжҖ§
жіЁж„ҸдёҠйқўзҡ„жЁЎеһӢжІЎжңүй»ҳи®Өзҡ„е…¬е…ұжһ„йҖ еҮҪж•°гҖӮEF Core з”ЁиҮӘеҠЁеұһжҖ§еҢ№й…Қжһ„йҖ еҮҪж•°еҸӮж•°гҖӮ
рҹ‘Қ еҲ йҷӨдёҚеҝ…иҰҒзҡ„еұһжҖ§е’Ңеӯ—ж®өзҡ„и®ҫзҪ®з¬ҰгҖӮ
дҪҝз”Ёж•°жҚ®еұӮйЎ№зӣ®и®© EF Core зҹҘйҒ“еҰӮдҪ•еңЁжІЎжңүи®ҫзҪ®еҷЁзҡ„жғ…еҶөдёӢеЎ«е……еұһжҖ§е’Ңеӯ—ж®өгҖӮ
иҝҷжҳҜз”Ёе®һзҺ° IEntityTypeConfiguration<T>зҡ„зұ»жқҘе®ҢжҲҗзҡ„гҖӮ
жҲ‘дҪҝз”Ёзҡ„жҳҜдёҖдёӘжӢҘжңүзұ»еһӢзҡ„дҫӢеӯҗпјҢиҜҘзұ»еһӢе°Ҷиў«з”ЁдҪңеҖјеҜ№иұЎ--иҝҷе°ұжҳҜдёәд»Җд№ҲдҪ дјҡзңӢеҲ°жүҖжңүйўқеӨ–зҡ„ж–№жі•е’Ңж“ҚдҪңз¬ҰйҮҚиҪҪжқҘжЈҖжҹҘе№ізӯүгҖӮ
жҲ‘дҪҝз”Ёзҡ„жҳҜдёҖдёӘеҖјеҜ№иұЎзҡ„дҫӢеӯҗпјҢеӣ дёәиҝҷж—¶дҪ йҖҡеёёдјҡжғіиҰҒж‘Ҷи„ұжүҖжңүзҡ„ setter--з”ҡиҮіжҳҜеҶ…йғЁжҲ–з§Ғжңүзҡ„ setterгҖӮ
рҹ‘Қ е°ҶйӣҶеҗҲж”№дёәеҸӘиҜ»
дёәйӣҶеҗҲдҪҝз”Ёз§Ғжңүеӯ—ж®өпјҢ并дҪҝз”ЁдёҚеҸҜеҸҳзҡ„йӣҶеҗҲжқҘжҡҙйңІе®ғ们пјҢеҰӮ IReadOnlyCollection<T>жҲ– IReadOnlyList<T>гҖӮ然еҗҺи®© EF ж ёеҝғзҹҘйҒ“еҰӮдҪ•еңЁжЈҖзҙўж—¶еЎ«е……з§ҒжңүйӣҶеҗҲпјҢйҖҡиҝҮй…ҚзҪ®е®ғзҡ„е…ғж•°жҚ®еҜјиҲӘеұһжҖ§пјҢеҰӮдёӢжүҖзӨә:
йҖҡиҝҮи°ғз”Ё Author зҡ„ж–№жі•еҸӘе…Ғи®ёж·»еҠ е’ҢеҲ йҷӨд№ҰзұҚпјҢдҪ жҠҠйҖ»иҫ‘йӣҶдёӯиө·жқҘдәҶгҖӮ
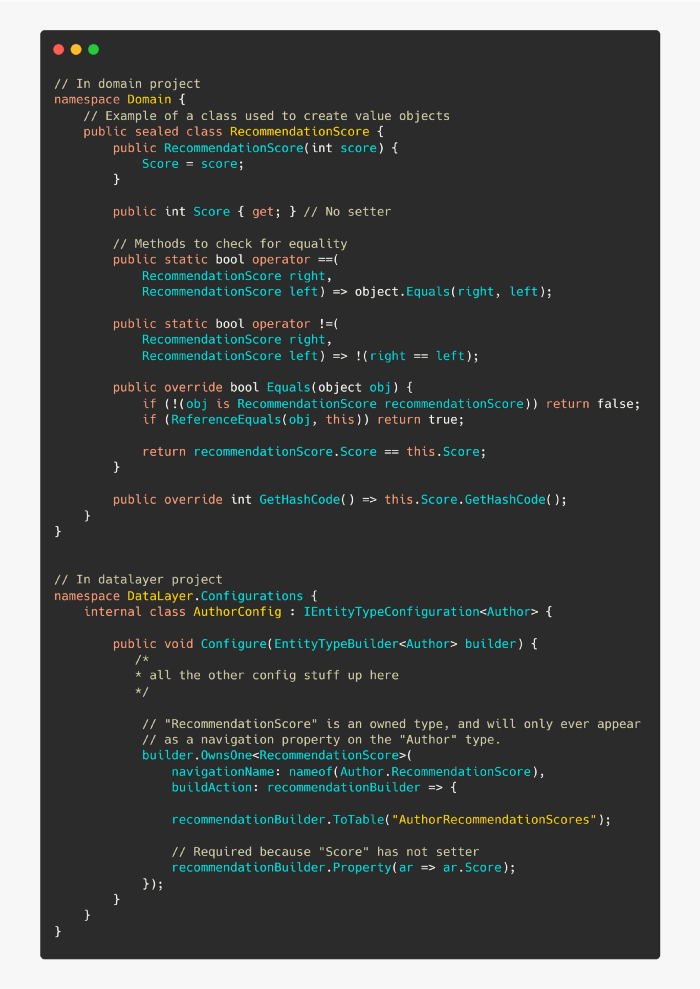
рҹ‘Қ дҪҝз”ЁиҮӘжңүзұ»еһӢ
иҮӘжңүзұ»еһӢжҳҜдёҖз§ҚеҸӘдјҡеҮәзҺ°еңЁе…¶д»–зұ»еһӢзҡ„еҜјиҲӘеұһжҖ§дёҠзҡ„зұ»еһӢгҖӮ
иҮӘжңүзұ»еһӢйҖҡеёёдёҚжҳҜе®һдҪ“жң¬иә«пјҢиҖҢжҳҜдҫқиө–дәҺе…¶д»–зұ»еһӢеӯҳеңЁжҲ–д»·еҖјеҜ№иұЎзҡ„зұ»еһӢгҖӮиҝҷдәӣзұ»еһӢжңҖеҘҪдёҚиҰҒжңү idгҖӮ
е°Ҫз®Ў RecommendationScore еңЁ POCO дёӯжІЎжңүдё»й”®пјҢдҪҶж•°жҚ®еә“дёӯдјҡдёәе®ғз”ҹжҲҗдёҖдёӘдё»й”®гҖӮе®ғйҮҮз”ЁдәҶдҪңиҖ…зҡ„дё»й”®пјҢеӣ дёәжҲ‘们已з»Ҹй…ҚзҪ®еҘҪдәҶпјҢдҪңиҖ…еҸӘиғҪжңүдёҖдёӘ RecommendationScoreгҖӮ
dotnet ef CLI
рҹҡЁ дёҚиҰҒдҪҝз”Ё Visual Studio её®еҠ©е‘Ҫд»Ө
еңЁжҲ‘зңӢжқҘпјҢVisual Studio йҡҗи—ҸдәҶеӨӘеӨҡзҡ„дёңиҘҝпјҢеҪ“дҪ еңЁдҪҝз”Ё.NET ж—¶пјҢеҢ…жӢ¬ EF CoreгҖӮ
д№ жғҜдәҶйӯ”жі•пјҢе°ұдјҡйҳ»зўҚдҪ жҺ’йҷӨж•…йҡңзҡ„иғҪеҠӣпјҢ并дҪҝдҪ еұҖйҷҗдәҺ VSгҖӮ
рҹ‘Қ дҪҝз”Ё dotnet ef е‘Ҫд»ӨиЎҢжҺҘеҸЈгҖӮ
е®үиЈ… dotnet ef жқҘжү§иЎҢ EF ж ёеҝғе‘Ҫд»ӨгҖӮ
dotnet tool install --gobal dotnet-efеңЁдҪ зҡ„ж•°жҚ®еұӮйЎ№зӣ®дёӯпјҢе®үиЈ… Microsoft.EntityFrameworkCore.DesignгҖӮиҝҷдёӘеҢ…иў« EF CLI з”ЁжқҘжү§иЎҢиҝҒ移гҖҒжӣҙж–°ж•°жҚ®еә“зӯүгҖӮ
dotnet add package Microsoft.EntityFrameworkCore.DesignеҪ“дҪҝз”Ё CLI ж—¶пјҢдҪ е°ҶиҺ·еҫ—дёҖдәӣе®қиҙөзҡ„гҖҒеҸҜиҪ¬з§»зҡ„жҠҖиғҪгҖӮдҪ дјҡжӣҙе®№жҳ“ең°и®ҫзҪ® Code as InfrastructureгҖҒDevOps з®ЎйҒ“гҖҒи°ғиҜ•зӯүгҖӮ
и®°дҪҸпјҢеҸӘжңү Visual Studio жүҚзҹҘйҒ“иҮӘе·ұзҡ„йӯ”еҠӣгҖӮеҪ“дҪ ејҖе§Ӣжһ„е»әз®ЎйҒ“ж—¶пјҢдҪ еҸҜд»ҘдёҚеҶҚдҫқиө– Visual Studio е‘Ҫд»ӨгҖӮеғҸ Update-Database иҝҷж ·зҡ„е‘Ҫд»Өж №жң¬ж— жі•е®һзҺ°гҖӮ
иҝҒ移
рҹ‘Қ е»әз«Ӣз®ҖжҳҺгҖҒеҸҜз®ЎзҗҶзҡ„иҝҒ移гҖӮ
жҜҸж¬ЎеҜ№жЁЎеһӢжҲ–жЁЎеһӢй…ҚзҪ®иҝӣиЎҢжӣҙж–°ж—¶пјҢиҜ·иҝҗиЎҢ ef migrations е‘Ҫд»ӨгҖӮ
dotnet ef migrations add MigrationNameе°ҪйҮҸдёҚиҰҒе°ҶдёҚзӣёе…ізҡ„жЁЎеһӢжӣҙж–°жҚҶз»‘еҲ°еҗҢдёҖдёӘиҝҒ移дёӯпјҢд»ҘдҝқжҢҒиҝҒ移зҡ„еҸҜз®ЎзҗҶжҖ§гҖӮ
рҹ‘Қ жЈҖжҹҘиҝҒ移代з ҒжҳҜеҗҰжӯЈзЎ®
жҖ»жҳҜжү“ејҖж–°еҲӣе»әзҡ„иҝҒ移пјҢ并йҳ…иҜ»иҮӘеҠЁз”ҹжҲҗзҡ„д»Јз ҒгҖӮ
еҫҲеӨҡж—¶еҖҷжҲ‘еҸ‘зҺ°жҲ‘йңҖиҰҒи°ғж•ҙжҲ‘зҡ„жЁЎеһӢй…ҚзҪ®пјҢеӣ дёә EF Core еҸҜиғҪжІЎжңүжӯЈзЎ®жіЁеҶҢдёҖдёӘе…ізі»гҖӮ
рҹҡЁ дёҚиҰҒиҝҗиЎҢ dotnet ef database update
йҷӨдәҶдҪ иҮӘе·ұзҡ„жң¬ең°ж•°жҚ®еә“д№ӢеӨ–пјҢеҚғдёҮдёҚиҰҒеҜ№е…¶д»–д»»дҪ•дёңиҘҝиҝҗиЎҢж•°жҚ®еә“жӣҙж–°е‘Ҫд»ӨгҖӮ
рҹ‘Қ дҪҝз”Ёе№Ӯзӯүи„ҡжң¬еҲӣе»әе’Ңжӣҙж–°ж•°жҚ®еә“
е№Ӯзӯүи„ҡжң¬зЎ®дҝқеҸӘжңүжІЎжңүиҝҗиЎҢзҡ„иҜӯеҸҘжүҚдјҡиў«жү§иЎҢгҖӮеҪ“еҲӣе»әдёҖдёӘе№Ӯзӯүж•°жҚ®еә“и„ҡжң¬ж—¶пјҢдҪ еҸҜд»Ҙж”ҫеҝғең°еӨҡж¬Ўжү§иЎҢж•ҙдёӘи„ҡжң¬гҖӮ
dotnet ef migrations script -v \ -o ./scripts/idempotent.sql \ --idempotentдёҠйқўзҡ„е‘Ҫд»Өе°ҶдҪҝз”ЁжүҖжңүзҺ°жңүзҡ„иҝҒ移з”ҹжҲҗдёҖдёӘи„ҡжң¬пјҢ并添еҠ IF жқЎд»¶жқҘжЈҖжҹҘжҳҜеҗҰе·Із»Ҹжү§иЎҢдәҶиҝҒ移гҖӮ
е°Ҷи„ҡжң¬дҝқеӯҳеңЁжәҗд»Јз ҒжҺ§еҲ¶дёӯпјҢеңЁдёҖдёӘеҗҲзҗҶзҡ„дҪҚзҪ®гҖӮ然еҗҺеңЁдҪ зҡ„йғЁзҪІиҝҮзЁӢдёӯжӢҝиө·е№¶жү§иЎҢиҜҘи„ҡжң¬гҖӮ
рҹ‘Қ дёәз§Қеӯҗж•°жҚ®еҲӣе»әиҝҒ移
йҖҡиҝҮе°ҶдҪ зҡ„з§Қеӯҗж•°жҚ®ж”ҫеңЁиҝҒ移дёӯпјҢж•°жҚ®е°ҶиҮӘеҠЁжҲҗдёәе№Ӯзӯүи„ҡжң¬зҡ„дёҖйғЁеҲҶгҖӮ
иҝҷж ·еҒҡпјҢдҪ е°ҶдјҡзңҒеҺ»еҫҲеӨҡдёҺд№Ӣзӣёе…ізҡ„еӨҙз–јзҡ„дәӢжғ…пјҢдҫӢеҰӮжҢүйЎәеәҸиҝҗиЎҢеҗҺз»ӯзҡ„и„ҡжң¬гҖӮ
рҹ‘Қ и®°еҪ•иҝҒ移е·ҘдҪңжөҒзЁӢ
еҫҲе®№жҳ“еҝҳи®°йҮҚж–°еҲӣе»әжҲ–жӣҙж–°ж•°жҚ®еә“жүҖйңҖзҡ„жүҖжңүжӯҘйӘӨгҖӮи®°еҪ•е·ҘдҪңжөҒзЁӢпјҢ并е°Ҷж–ҮжЎЈж Үи®°ж–Ү件дҝқеӯҳеңЁж•°жҚ®еұӮйЎ№зӣ®ж №зӣ®еҪ•дёӢгҖӮ
дҫҝдәҺеӨҚеҲ¶еҲ°жӮЁиҮӘе·ұзҡ„ .md ж–Ү件дёӯгҖӮ
## Intro All commands must be executed from the root of the data layer project. 1. cd to root of data layer project ### Add new migration dotnet ef migrations add <MigrationName> -s ../Path/To/StartupProj <MigrationName> вҶҗ name of the migration, without <> ### Remove most recent migration dotnet ef migrations remove -s ../Path/To/StartupProj ### Update local(!) database dotnet ef database update -s ../Path/To/StartupProj ^ this must only ever be used to update your own local database ### Generate idempotent script dotnet ef migrations script -v -i \ -o ./scripts/idempotent.sql \ -s ../Path/To/StartupProj ## Switches -v вҶҗ verbose console output -o вҶҗ path to where generated script file is placed -i вҶҗ makes the script idempotent -s вҶҗ Path to startup project (e.g. ASP.NET web app .csproj)