
efcoreжҖ§иғҪжҸҗеҚҮ.md 7.8 KB
жҸҗй«ҳ.NET Core еә”з”Ёдёӯ EF Core жҖ§иғҪзҡ„ 3 з§Қж–№жі•
ORMпјҲеҜ№иұЎе…ізі»жҳ е°„пјүжЎҶжһ¶зЎ®е®һз®ҖеҢ–дәҶејҖеҸ‘дәәе‘ҳеңЁжүҖжңүж•°жҚ®еә“зӣёе…ід»»еҠЎдёӯзҡ„з”ҹжҙ»гҖӮ
然иҖҢпјҢйҖҡеёёжғ…еҶөдёӢпјҢиҝҷз§Қз®ҖеҢ–жҳҜжңүд»Јд»·зҡ„гҖӮеңЁеӨ§еӨҡж•°жғ…еҶөдёӢпјҢд»Јд»·жҳҜзҒөжҙ»жҖ§е’ҢжҖ§иғҪгҖӮ
еңЁжң¬ж–ҮдёӯпјҢжҲ‘е°Ҷд»Ӣз»Қдёүз§ҚжңҖз®ҖеҚ•зҡ„ж–№жі•жқҘжҸҗй«ҳдҪ зҡ„ .NET Core еә”з”ЁзЁӢеәҸдёӯ Entity Framework CoreпјҲEF Coreпјүж“ҚдҪңзҡ„жҖ§иғҪгҖӮ
1. дёҚиҰҒеҒ·жҮ’гҖӮиҰҒжҖҘдәҺжұӮжҲҗ
жҲ‘们е…Ҳд»ҺжңҖжҳҺжҳҫзҡ„е»әи®®иҜҙиө·пјҢе…¶е®һеңЁжҹҗдәӣжғ…еҶөдёӢпјҢEF Core дҪҝз”ЁдёҚеҪ“пјҢеҸҜд»Ҙз»ҷдҪ жңҖеӨ§зҡ„жҖ§иғҪжҸҗеҚҮгҖӮ
жүҖд»ҘпјҢжғіиұЎдёҖдёӘеҫҲеёёи§Ғзҡ„жғ…еҶө:
- дҪ еңЁдёӨдёӘе®һдҪ“д№Ӣй—ҙжңүдёҖдёӘдё»д»Һе…ізі»гҖӮи®©е®ғжҲҗдёәдёҖдёӘз»Ҹе…ёзҡ„и®ўеҚ•-е®ўжҲ·зҡ„дҫӢеӯҗпјҢе…¶дёӯжҜҸдёӘи®ўеҚ•е®һдҪ“еј•з”ЁдёҖдёӘе®ўжҲ·гҖӮ
- жӮЁйңҖиҰҒжЈҖзҙўжҢҮе®ҡж—¶жңҹпјҲдҫӢеҰӮд»Һд»Ҡе№ҙе№ҙеҲқејҖе§Ӣпјүзҡ„жүҖжңүи®ўеҚ•дҝЎжҒҜпјҢ并жҳҫзӨәжҜҸдёӘи®ўеҚ•зҡ„е®ўжҲ·еҗҚз§°гҖӮ
EF Core 2.1 еј•е…ҘдәҶдёҖдёӘеҸ«еҒҡ "жҮ’еҠ иҪҪ "зҡ„дёңиҘҝпјҲжҲ–иҖ…иҜҙжҳҜ "йҮҚж–°еј•е…Ҙ"пјҢеӣ дёәиҝҷдёӘеҠҹиғҪеңЁиҖҒејҸзҡ„ Entity Framework 6.x дёӯжҳҜеҸҜз”Ёзҡ„пјүпјҢжүҖд»ҘзҺ°еңЁдҪ еҸҜд»Ҙз®ҖеҚ•ең°з”ЁдёӢйқўзҡ„д»Јз ҒжқҘе®һзҺ°жүҖиҝ°д»»еҠЎгҖӮ
var thisYearFirstDay = new DateTime(DateTime.Now.Year, 1, 1);
var thisYearOrders = context.Orders
.Where(o => o.OrderDate > thisYearFirstDay);
foreach (var order in thisYearOrders)
{
Console.WriteLine($"{order.Id} {order.OrderDate} {order.Customer.CompanyName}");
}
еҫҲз®ҖеҚ•пјҢеҜ№дёҚеҜ№пјҹ
й”ҷдәҶ! е…¶е®һеҫҲеҒ·жҮ’:)пјҢдҪҝз”Ёиҝҷж®өд»Јз ҒдҪ дјҡеҫ—еҲ°е·ЁеӨ§зҡ„жҖ§иғҪжү“еҮ»гҖӮ
дёәд»Җд№Ҳиҝҷд№ҲиҜҙе‘ўпјҹеҫҲз®ҖеҚ•пјҢеӣ дёә EF Core дјҡе°ҶдҪ зҡ„д»Јз ҒиҪ¬жҚўдёә 1+N жҹҘиҜўеҲ°ж•°жҚ®еә“пјҢе…¶дёӯ N-жҳҜ thisYearOrders з»“жһңйӣҶдёӯзҡ„и®°еҪ•ж•°гҖӮ
еҰӮжһңдҪ еңЁдҪ зҡ„ DbContext дёӯж·»еҠ дёҖдёӘи®°еҪ•еҷЁпјҢ并жҹҘзңӢи®°еҪ•ж¶ҲжҒҜпјҢдҪ дјҡзңӢеҲ°иҝҷж ·дёҖдёӘжҹҘиҜў:
SELECT [o].[OrderID], [o].[CustomerID], . . .
FROM [Orders] AS [o]
WHERE [o].[OrderDate] > @__thisYearFirstDay_0
然еҗҺ N ж¬Ўиҝҷж ·зҡ„жҹҘиҜў:
SELECT [e].[CustomerID], [e].[Address], . . .
FROM [Customers] AS [e]
WHERE [e].[CustomerID] = @__get_Item_0
жҳҫ然пјҢиҝҷж ·зҡ„жҹҘиҜўж¬Ўж•°дјҡиҖ—иҙ№еӨ§йҮҸзҡ„ж—¶й—ҙпјҢе°Өе…¶жҳҜеңЁиҝһжҺҘдёҚз•…жҲ–ж•°жҚ®еә“еәһеӨ§зҡ„жғ…еҶөдёӢгҖӮ
дёәдәҶи§ЈеҶіиҝҷдёӘй—®йўҳпјҢжҲ‘们еҸӘйңҖиҰҒдҪҝз”ЁжүҖи°“зҡ„ "жҖҘеҲҮеҠ иҪҪ"пјҢ并еңЁжҲ‘们зҡ„иҜ·жұӮдёӯж·»еҠ Includeи°ғз”Ё:
var thisYearOrders = context.Orders
.Include(o => o.Customer)
.Where(o => o.OrderDate > thisYearFirstDay);
зҺ°еңЁпјҢеҰӮжһңжҲ‘们зңӢдёҖдёӢжҲ‘们зҡ„ж—Ҙеҝ—пјҢжҲ‘们дјҡзңӢеҲ°еҸӘжңүдёҖдёӘжҹҘиҜўпјҢиҖҢдёҚжҳҜ 1+N:
SELECT [o].[OrderID], [o].[CustomerID], . . . /* all other columns from Orders and Customers */
FROM [Orders] AS [o]
LEFT JOIN [Customers] AS [o.Customer] ON [o].[CustomerID] = [o.Customer].[CustomerID]
WHERE [o].[OrderDate] > @__thisYearFirstDay_0
жӯЈеҰӮдҪ жүҖжғізҡ„йӮЈж ·пјҢ"жҖҘдәҺжұӮжҲҗ "зҡ„ж–№жі•дјҡжҜ” "жҮ’жғ° "зҡ„ж–№жі•жү§иЎҢеҫ—жӣҙеҝ«гҖӮ
еңЁе®һйҷ…еә”з”ЁдёӯпјҢиҝҷз§ҚдјҳеҠҝзҡ„д»·еҖјеҸҜд»ҘжҳҜеҮ зҷҫз”ҡиҮідёҠеҚғзҡ„зҷҫеҲҶжҜ”!
2. дёҚиҰҒжҖҘдәҺжұӮжҲҗеӨҡгҖӮеҸӘжӢҝдҪ иҰҒз”Ёзҡ„дёңиҘҝ
жҲ‘们第дёҖдёӘдҫӢеӯҗдёӯзҡ„ "жҖҘеҲҮ "ж–№жі•зҡ„й—®йўҳжҳҜпјҢе®ғеңЁеӨ§еӨҡж•°жғ…еҶөдёӢеҸҜиғҪиҝҮдәҺ "жҖҘеҲҮ"гҖӮ
зңӢпјҢжҲ‘们е®һйҷ…дёҠеҸӘйңҖиҰҒдёүдёӘеӯ—ж®өпјҲдёӨдёӘжқҘиҮӘ Orders иЎЁпјҢдёҖдёӘжқҘиҮӘ Customers иЎЁпјүпјҢдҪҶжҲ‘们еҚҙд»ҺдёӨдёӘиЎЁдёӯеҸ–дәҶж•ҙз»„еҲ—гҖӮ
и§ЈеҶіж–№жі•еҫҲз®ҖеҚ•пјҡз”Ё Select и°ғз”ЁеҸӘеҸ–дҪ йңҖиҰҒзҡ„йӮЈдәӣеҲ—:
var thisYearFirstDay = new DateTime(DateTime.Now.Year, 1, 1);
var thisYearOrders = context.Orders
.Where(o => o.OrderDate > thisYearFirstDay)
.Select(o => new { o.Id, o.OrderDate, o.Customer.CompanyName })
foreach (var rec in thisYearOrders)
{
Console.WriteLine($"{rec.Id} {rec.OrderDate} {rec.CompanyName}");
}
з”ұжӯӨдә§з”ҹзҡ„ SQL иҜӯеҸҘе°ҶжҳҜиҝҷж ·зҡ„:
SELECT [o].[OrderID] AS [Id], [o].[OrderDate], [o.Customer].[CompanyName]
FROM [Orders] AS [o]
LEFT JOIN [Customers] AS [o.Customer] ON [o].[CustomerID] = [o.Customer].[CustomerID]
WHERE [o].[OrderDate] > @__thisYearFirstDay_0
е®ғиӮҜе®ҡдјҡжңүжӣҙеҘҪзҡ„жҖ§иғҪпјҢеӣ дёәд»Һ DB жңҚеҠЎеҷЁеҲ°е®ўжҲ·з«ҜпјҲеңЁиҝҷз§Қжғ…еҶөдёӢпјҢдҪ зҡ„.NET еә”з”ЁзЁӢеәҸпјүдј иҫ“зҡ„ж•°жҚ®дјҡеҮҸе°‘гҖӮ
еңЁдёҠйқўзҡ„д»Јз ҒдёӯпјҢжңүдёӨзӮ№йңҖиҰҒжіЁж„ҸгҖӮ
йҰ–е…ҲпјҢжҲ‘们дёҚеҶҚйңҖиҰҒ Include и°ғз”ЁпјҢеӣ дёә Entity Framework д»Һ Select и°ғз”Ёдёӯ "зҗҶи§Ј "дәҶжҲ‘们йңҖиҰҒдёҖдёӘжқҘиҮӘеҸҰдёҖдёӘиЎЁзҡ„еӯ—ж®ө(Customer.CompanyName)пјҢ并иҮӘеҠЁе°Ҷеҝ…иҰҒзҡ„ JOIN еӯҗеҸҘж·»еҠ еҲ°з»“жһң SQL дёӯгҖӮ
е…¶ж¬ЎпјҢжӯЈеҰӮдҪ жүҖзңӢеҲ°зҡ„пјҢжҲ‘们е®һйҷ…дёҠз”Ёж–°зҡ„{o.IdпјҢ...}е‘Ҫд»ӨеҲӣе»әдәҶдёҖдёӘеҠЁжҖҒеҜ№иұЎеҲ—иЎЁпјҲдёҚеұһдәҺд»»дҪ•зү№е®ҡзұ»зҡ„еҜ№иұЎпјүгҖӮ
дёәдәҶејәи°ғиҝҷдёӘдәӢе®һпјҢжҲ‘们е°Ҷ foreach еҫӘзҺҜдёӯзҡ„еҸҳйҮҸеҗҚд»Һ order жӣҝжҚўжҲҗдәҶ recпјҲжқҘиҮӘ "rec и®°еҪ•"пјү--еӣ дёәе®ғе·Із»ҸдёҚжҳҜдёҖдёӘ "order "дәҶгҖӮжҲ‘们еңЁз»“жһңдёӯеҫ—еҲ°зҡ„еҠЁжҖҒеҜ№иұЎеҸӘеҢ…еҗ« 3 дёӘеұһжҖ§гҖӮIdгҖҒOrderDate е’Ң CompanyNameпјҲиҝҷе°ұжҳҜдёәд»Җд№ҲжҲ‘们зҺ°еңЁзӣҙжҺҘи®ҝй—® "CompanyName "иҖҢдёҚжҳҜд№ӢеүҚзҡ„ "order.Customer.CompanyName"пјүгҖӮ
3. дҪҝз”Ё AsNoTracking()гҖӮдҪҶиҰҒжҳҺжҷәең°дҪҝз”Ё
еҪ“дҪ еңЁ DbContext дёӯзҡ„дёҖдәӣе®һдҪ“дёҠиҝҗиЎҢжҹҘиҜўж—¶пјҢиҝ”еӣһзҡ„еҜ№иұЎдјҡиў«дёҠдёӢж–ҮиҮӘеҠЁи·ҹиёӘпјҢд»Ҙе…Ғи®ёдҪ дҝ®ж”№е®ғ们пјҲеҰӮжһңйңҖиҰҒпјүпјҢ然еҗҺз”Ё context.SaveChanges()ж“ҚдҪңдҝқеӯҳжӣҙж”№гҖӮ
然иҖҢпјҢеҰӮжһңиҝҷжҳҜдёҖдёӘеҸӘиҜ»жҹҘиҜўпјҢиҖҢдё”иҝ”еӣһзҡ„ж•°жҚ®дёҚеә”иҜҘиў«дҝ®ж”№пјҢйӮЈд№Ҳе°ұжІЎжңүеҝ…иҰҒи®©дёҠдёӢж–Үжү§иЎҢдёҖдәӣе»әз«Ӣиҝҷз§Қи·ҹиёӘжүҖйңҖзҡ„йўқеӨ–е·ҘдҪңгҖӮAsNoTracking ж–№жі•е‘ҠиҜү Entity Framework еҒңжӯўиҝҷз§ҚйўқеӨ–зҡ„е·ҘдҪңпјҢеӣ жӯӨпјҢе®ғеҸҜд»ҘжҸҗй«ҳеә”з”ЁзЁӢеәҸзҡ„жҖ§иғҪгҖӮ
жүҖд»ҘпјҢд»ҺзҗҶи®әдёҠи®ІпјҢжңү AsNoTracking зҡ„жҹҘиҜўеә”иҜҘжҜ”жІЎжңү AsNoTracking зҡ„жҹҘиҜўжҖ§иғҪжӣҙеҘҪгҖӮй—®йўҳжҳҜпјҡеҘҪеӨҡе°‘пјҹи®©жҲ‘们жқҘеј„жё…жҘҡгҖӮ
жҲ‘дҪҝз”Ё BenchmarkDotNet еә“еҲӣе»әдәҶдёҖдёӘе°ҸеһӢжөӢиҜ•еә”з”ЁзЁӢеәҸгҖӮиҝҷйҮҢжңүдёӨдёӘиў«жЈҖжҹҘзҡ„еҮҪж•°:
public void GetAll_WithTracking()
{
var allRecords = _dbContext.OrderDetails;
var list = allRecords.ToList();
}
public void GetAll_NoTracking()
{
var allRecords = _dbContext.OrderDetails.AsNoTracking();
var list = allRecords.ToList();
}
жӯЈеҰӮжҲ‘们жүҖжңҹжңӣзҡ„йӮЈж ·пјҢ"NoTracking "ж–№ејҸиЎЁзҺ°еҫ—жӣҙеҘҪгҖӮдёҖиҲ¬жқҘиҜҙпјҢе®ғдјјд№ҺжҜ” "WithTracking "еҝ« 1.5 еҖҚгҖӮ
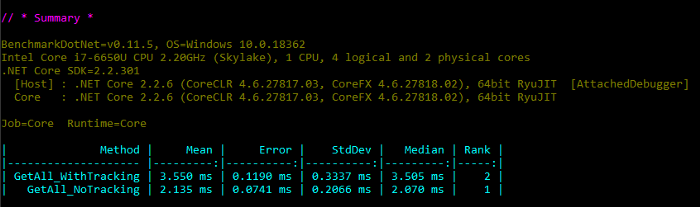
еҪ“жҲ‘们иҜ•еӣҫе°Ҷ AsNoTracking ж·»еҠ еҲ°еҜ№дёӨдёӘиЎЁзҡ„жҹҘиҜўдёӯж—¶пјҢеҘҮжҖӘзҡ„дәӢжғ…е°ұејҖе§ӢдәҶпјҲжңү JOINпјү:
public void GetWithInclude_Tracking()
{
var allRecords = _dbContext.OrderDetails
.Include(od => od.Product);
var list = allRecords.ToList();
}
public void GetWithInclude_NoTracking()
{
var allRecords = _dbContext.OrderDetails
.AsNoTracking()
.Include(od => od.Product);
var list = allRecords.ToList();
}
з»“жһңд»Өдәәеӣ°жғ‘:
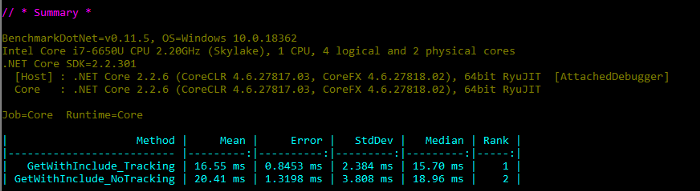
жңүи·ҹиёӘзҡ„жҹҘиҜўжҜ”жІЎжңүи·ҹиёӘзҡ„жҹҘиҜўжҖ§иғҪзЁҚеҘҪпјҒеңЁ GitHub дёҠжңүдёҖдёӘй—®йўҳпјҢе…ідәҺиҝҷз§ҚеҘҮжҖӘзҡ„иЎҢдёәпјҲ第дёҖзңјзңӢдёҠеҺ»пјүгҖӮ
еңЁ GitHub дёҠжңүдёҖдёӘе…ідәҺиҝҷз§ҚеҘҮжҖӘпјҲд№ҚдёҖзңӢпјүиЎҢдёәзҡ„й—®йўҳгҖӮ
然иҖҢпјҢеҰӮжһңжҲ‘们е°қиҜ•жғіиұЎдёҖдёӢ Entity Framework еҶ…йғЁжҳҜеҰӮдҪ•е®һзҺ°зҡ„пјҢиҝҷз§ҚиЎҢдёәеҸҜиғҪжҳҜзӣёеҪ“з¬ҰеҗҲйҖ»иҫ‘зҡ„гҖӮиҝһжҺҘдёӨеј иЎЁзҡ„жҹҘиҜўйңҖиҰҒд»ҺдёӨеј иЎЁдёӯиҺ·еҸ–и®°еҪ•жқҘиҝӣиЎҢеҢ№й…ҚпјҢеҰӮжһңиҝҷдәӣи®°еҪ•е·Із»Ҹиў«дёҠдёӢж–Үи·ҹиёӘпјҢеӣ жӯӨпјҢеӯҳеӮЁеңЁеҶ…еӯҳдёӯпјҢжҳҫ然дјҡеҸ‘з”ҹеҫ—жӣҙеҝ«гҖӮ
дёҚиҝҮпјҢиҝҷеҸӘжҳҜжҲ‘зҡ„зҢңжөӢгҖӮеҰӮжһңдҪ жңүе…¶д»–жғіжі•пјҢиҜ·е‘ҠиҜүжҲ‘гҖӮ
з»“жқҹиҜӯ
жҲ‘еёҢжңӣжҲ‘еңЁжң¬ж–ҮдёӯеҲ—еҮәзҡ„е…ідәҺжҖ§иғҪж”№иҝӣзҡ„е»әи®®иғҪеё®еҠ©дҪ еҶҷеҮәжӣҙй«ҳж•Ҳзҡ„д»Јз ҒгҖӮ
жҲ‘еҸӘжғіеҶҚз»ҷдҪ дёҖдёӘдёҖиҲ¬жҖ§зҡ„е»әи®®гҖӮдҪҝз”Ёжәҗз Ғ:)
еңЁдҪҝз”Ё EF Core ж–№йқўпјҢиҝҷж„Ҹе‘ізқҖпјҡзңӢзңӢдҪ зҡ„д»Јз Ғз”ҹжҲҗзҡ„ SQL иҜӯеҸҘпјҲдҪ еҸҜд»ҘеңЁи°ғиҜ•ж—¶еңЁ VS зҡ„иҫ“еҮәйқўжқҝдёӯзңӢеҲ°е®ғ们пјүгҖӮ
е®ғеҸҜд»Ҙи®©дҪ дәҶи§Ј "еј•ж“Һзӣ–дёӢ "еҸ‘з”ҹдәҶд»Җд№ҲпјҢеңЁжҹҗдәӣжғ…еҶөдёӢпјҢеҸҜиғҪдјҡеё®еҠ©дҪ жҳҫи‘—жҸҗй«ҳдҪ зҡ„еә”з”ЁзЁӢеәҸзҡ„жҖ§иғҪгҖӮ